NVIDIA Visual Profiler
NVIDIA Visual Profiler提供了丰富的图形用户环境,可以给出CUDA在后台工作的更多细节。除了提供每个CUDA函数调用的时间分析外,它还能给出如何调用内核函数以及存储器的使用情况等。它有助于定位瓶颈可能出现的位置,并详细解释如何调用内核。
1.使用NVIDIA Visual Profiler进行CUDA分析
Visual Profiler是NVIDIA提供的图形化分析工具,其在成功安装CUDA toolkit后,就能够使用。通过Profiler能够对CUDA应用的CPU和GPU的时间节点进行分析,并能够调优CUDA应用的性能。Visual Profiler的简单使用方法如下所示:
- 启动:在控制终端输入命令:nvvp;如图 5所示的启动后界面。
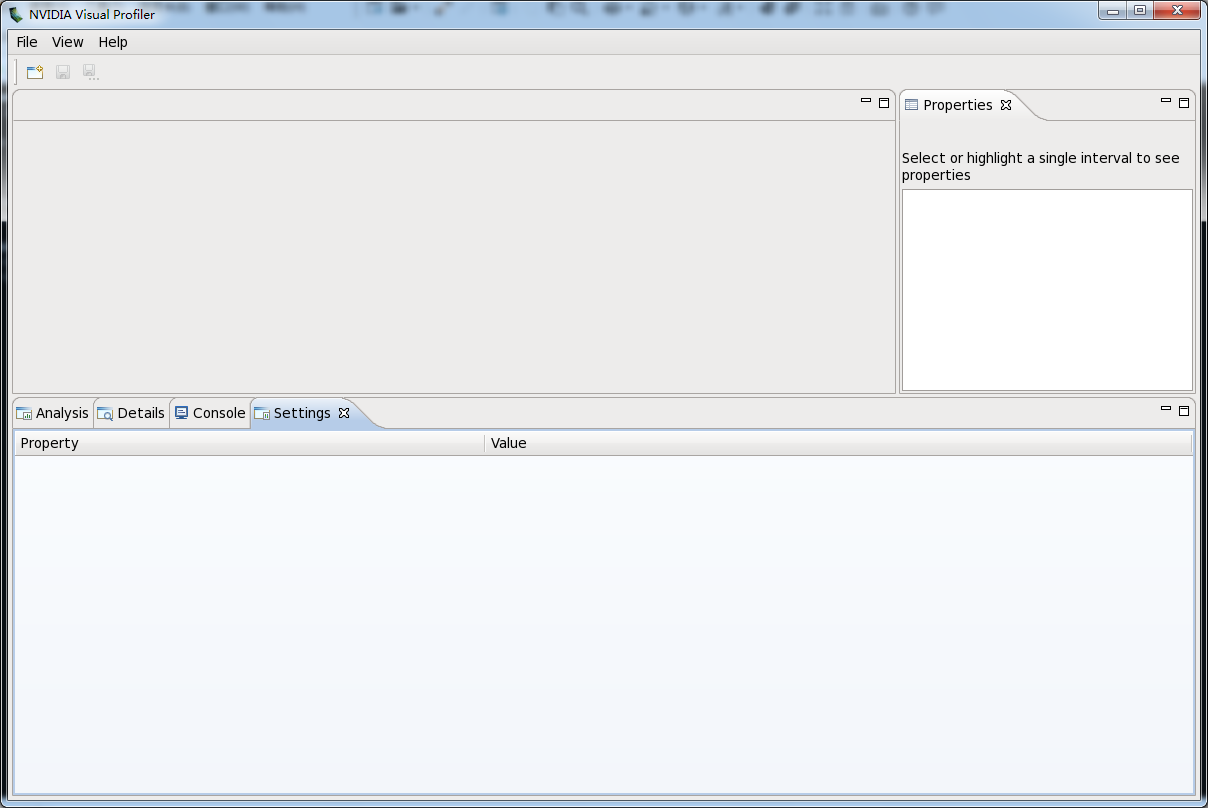
- 新建session:其创建入口为:FileNew Session,如图所示是新建Session对话框,在该对话框中的File输入框中输入需被分析的可执行文件。

- 分析结果:在新建Session对话框中输入相应的可执行文件后,就能产生分析结果,如图所示。

2.nvprof Profiler:命令行
通过nvprof可以以命令行的形式分析和调优CUDA应用程序。nvprof的使用形式是:
nvprof [options] [CUDA-application] [application-arguments]
- summary模型
这是nvprof的默认模型,在这个模型中只简单输出核函数和CUDA内存复制性能。如对于需要被测试的可执行文件boxFilterNPP,可直接执行命令:nvprof boxFilterNPP。如图所示的结果。

- GPU-Trace和API-Trace模型
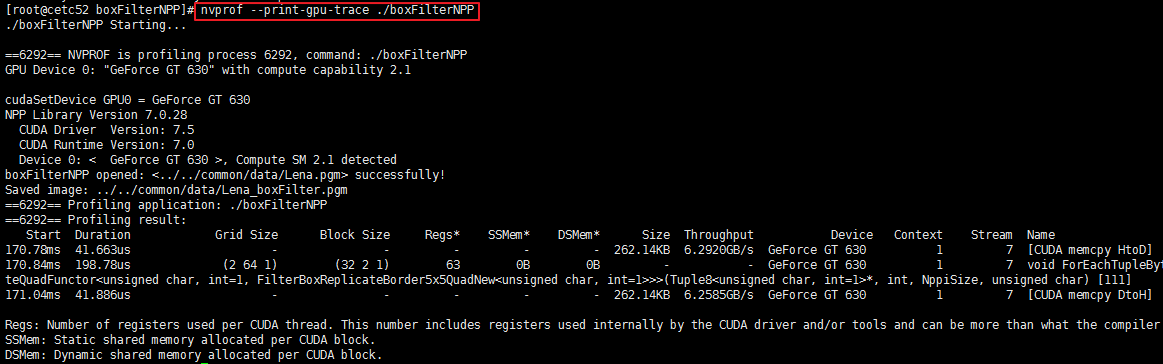
这个模型能够以时间轴顺序提供所有在GPU发生的活动点,每个核函数的执行或是复制/赋值都能够详细的显示。如图所示。
- Event/metric Summary模型
通过这个模型能够在指定的NVIDIA GPU上显示所有可用的Event/metric,
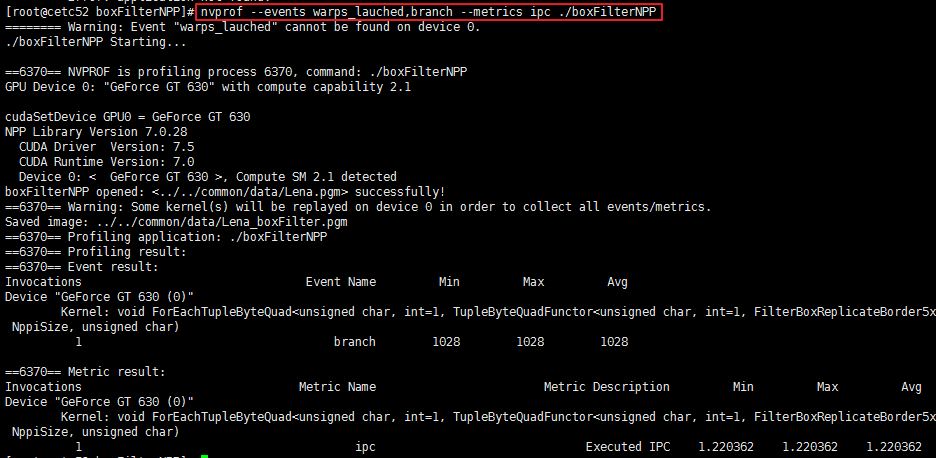
- Event/metric Trace Mode
通过这个模型能够显示每个核函数的event和metric值。如图所示。

使用Visual Profiler分析Python程序
- 命令行格式
1 | $ nvprof python train_mnist.py |
输出如下
1 | $ nvprof python examples/stream/cusolver.py [10/1910] |
可以增加额外参数,指定模式。
1 | $ nvprof --print-gpu-trace python train_mnist.py |
输出如下
1 | $ nvprof --print-gpu-trace python examples/stream/cusolver.py |
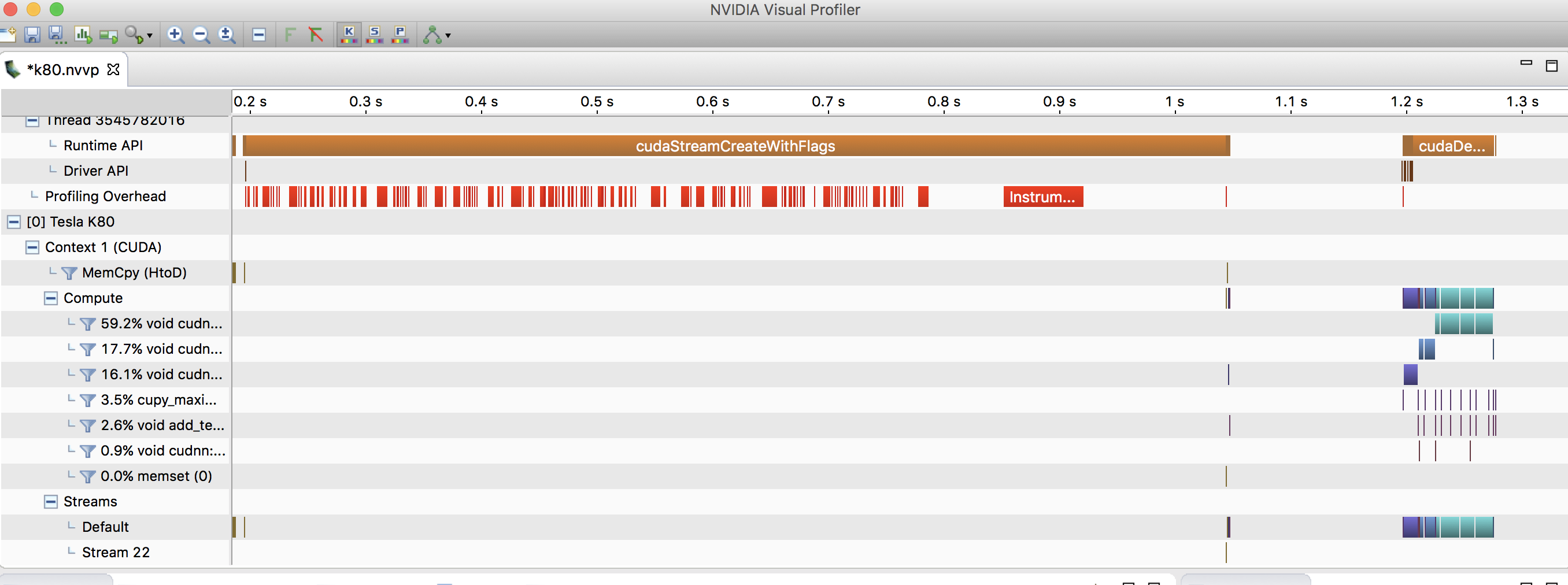
- 图形化界面
首先使用nvvp将记录文件输出
1 | $ nvprof -o prof.nvvp python train_mnist.py |
然后把.nvvp文件拷贝到要分析的文件夹下,启动nvidia visual profiler
1 | $ nvvp prof.nvvp |
输出如下

参考文献
- CUDA_Profiler_Users_Guide.pdf